
SQL执行计划及分页查询优化、分区键统计
常见业务处理
一、使用数据库处理常见业务:
案例: 如何对评论进行分页展示
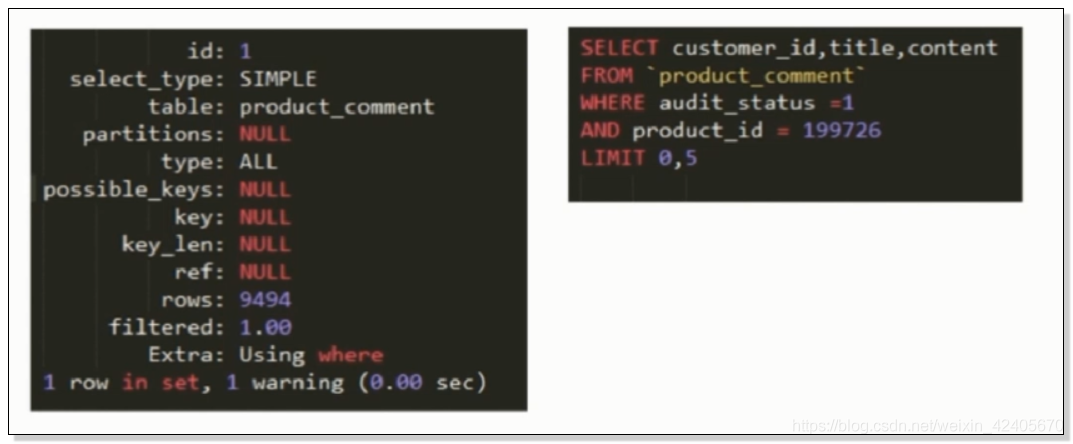
- 使用 EXPLAIN 获得sql的执行计划
EXPLAIN
SELECT customer_id,title,content
from `product_comment`
where audit_status = 1
and product_id = 199726
LIMIT 0,5;![]()
SELECT UPDATE INSERT REPLACE DELETE
二、执行计划
1、执行计划分析
执行计划能告诉我们什么?
- SQL如何使用索引
- 联接查询的执行顺序
- 查询扫描的数据行数
执行计划中的内容:
![]()
三、执行计划内容的作用分析及示例
1、 ID列
执行计划中的id列的意义:
- ID列中的数据为一组数字,表示执行SELECT语句的顺序
- ID值相同时,执行顺序由上至下
- ID值越大优先级越高,越先被执行
查看执行计划:
EXPLAIN SELECT
c.`category_name`,
a.`product_name`,
b.`title`
FROM
product_info a
JOIN product_comment b ON a.`product_id` = b.`product_id`
JOIN product_category c ON c.`category_id` = a.`one_category_id`;![]()
截图:

![]()
复杂sql查看执行计划:
EXPLAIN
select title
from product_comment
WHERE product_id in (
SELECT max(product_id)
from product_info
WHERE one_category_id in (select min(category_id) from product_category)
)![]()
截图:

![]()
组查询sql查看执行计划:
EXPLAIN
SELECT title
from (
SELECT one_category_id,max(product_id)AS pid
from product_info
GROUP BY one_category_id
) a JOIN product_comment b on a.pid = b.`product_id`![]()
截图:

![]()
2、SELECT_TYPE列

![]()
执行计划案例1:
EXPLAIN
SELECT title
FROM product_comment
WHERE
product_id IN (
SELECT max(product_id)
FROM product_info
WHERE
one_category_id IN (
SELECT min(category_id)
FROM product_category
)
);![]()

![]()
补充:

![]()
3、TABLE列
作用: 输出数据行所在的表的名称
- <unionM,N>由ID为M,N查询union产生的结果集
- <derivedN>/<subqueryN>由ID为N的查询产生的结果
执行计划案例1:
EXPLAIN
select product_category.`category_name`,product_info.`product_name`,product_comment.`title`
from product_info
JOIN product_comment on product_info.`product_id`=product_comment.`product_id`
JOIN product_category on product_category.`category_id`=product_info.`one_category_id`![]()

![]()
4、PARTITIONS列
作用: 对于分区表,显示查询的分区ID
对于非分区表,显示为NULL
执行计划案例:
EXPLAIN
SELECT *
FROM `crn`.`customer_login_log`
where customer_id = 1![]()

![]()
以用户登录日志为例,应该使用用户表的用户id作为分区条件进行数据的存储和归档,这样有利于将同一个用户的所有数据写入到同一个分区区间,有利于避免查询登录日志时会对大表进行查询过程中对其他用户的登录日志进行过滤而导致的效率损耗!
5、TYPE列

![]()
6、Extra列

![]()
7、POSSIBLE_KEYS列
①指出MySQL能使用那些索引来优化查询
②查询列所涉及到的列上的索引都会被列出,但不一定会被使用
8、KEY列
①查询优化器优化查询实际所使用的索引
②如果没有可用的索引,则显示为NULL
③如查询使用了覆盖索引,则该索引仅出现在Key列中
9、KEY_LEN 列
①表示索引字段的最大长度
②Key_len的长度由字段定义计算而来,并非数据的实际长度
10、Ref列
表示哪些列或常量被用于查找索引列上的值
11、rows列
①表示MySQL通过索引统计信息,估算的所需读取的行数
②Rows值的大小是个统计抽样结果,并不十分准确
12、Filtered列
①表示返回结果的行数占需读取行数的百分比
②Filtered列的值越大越好
③Filtered列的值依赖说统计信息
四、执行计划的限制
①无法展示存储过程,触发器,UDF对查询的影响
②无法使用EXPLAIN对存储过程进行分析
③早期版本的MySQL只支持对SELECT语句进行分析
五、优化分页查询示例
需求: 根据audit_status及product_id 创建联合索引,这里需要明确哪一个值放在联合索引的左侧,
由右上角的执行比率知道,使用product_id作为索引放在组合索引左侧是最合适的,因为其比值最接近于1。
创建执行计划:
EXPLAIN
SELECT customer_id,title,content
from product_comment
where audit_status=1
AND product_id=199727
limit 0,5![]()

![]()
初步优化,创建联合索引:
CREATE INDEX idx_productID_auditStats on product_comment(product_id,audit_status)![]()
经过添加索引优化后的执行计划执行结果:

![]()
其查询效率明显提高,由type列可知,由原来的ALL进行全表扫描查询降为非唯一索引查询。
进一步优化分页查询
SELECT t.customer_id,t.title,t.content
from (
SELECT `comment_id`
from product_comment
where product_id=199727 AND audit_status=1 LIMIT 0,5
) a JOIN product_comment t
ON a.comment_id = t.comment_id;![]()
优化说明: 先通过分页查询获取到对应数据的comment_id,此时的查询不会对其他字段进行查询返回,默认可以通过主键索引进行查询,效率极高;然后再讲查询到的a.commetn_id作为临时子表再与product_comment进行comment_id的匹配查询,此时直接通过comment_id进行查询返回包含comment_id在内的其他的字段。这种查询方式在IO上能节约很多的资源,当数据量上万时,效率依然不会受到太大影响。
六、如何删除重复数据
删除评论表中对同一订单同一商品的重复评论,只保留最早的一条
步骤一:查看是否存在对于一订单同一商品的重复评论
select order_id,product_id,COUNT(*)
from product_comment
GROUP BY order_id,product_id HAVING COUNT(*)>1![]()
步骤二:备份product_comment表
创建备份表:
CREATE TABLE `mc_productdb`.bak_product_comment_161022
LIKE `mc_productdb`.product_comment;![]()
同步表数据:
INSERT INTO `mc_productdb`.`bak_product_comment_161022`
select * from `mc_productdb`.`product_comment`;![]()
步骤三:删除同一订单的重复评论
DELETE a
FROM product_comment a
JOIN (
SELECT order_id,product_id,MIN(comment_id) AS comment_id
FROM product_comment
GROUP BY order_id,product_id
HAVING COUNT(*)>=2
) b ON a.order_id=b.order_id AND a.product_id=b.product_id
AND a.comment_id> b.comment_id![]()
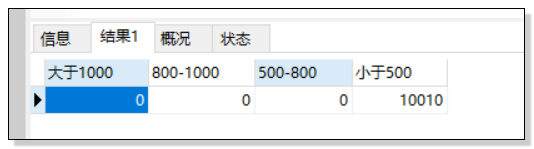
七、进行分区间统计
需求:统计消费总金额大于1000元的,800到1000元的,500到800元的,以及500元以下的人数
SELECT count(CASE WHEN IFNULL(total_money,0) >=1000 THEN a.customer_id END) AS '大于1000'
,count(CASE WHEN IFNULL(total_money,0) >=800 AND IFNULL(total_money,0)<1000
THEN a.customer_id END) AS '800-1000'
,count(CASE WHEN IFNULL(total_money,0) >=800 AND IFNULL(total_money,0)<800
THEN a.customer_id END) AS '500-800'
,count(CASE WHEN IFNULL(total_money,0) <500 THEN a.customer_id END) '小于500'
from mc_userdb.customer_login a
LEFT JOIN
( SELECT customer_id,SUM(order_money) AS total_money
from mc_orderdb.`order_master` GROUP BY customer_id) b
ON a.customer_id=b.customer_id
![]()

八、捕获有问题的SQL
核心:利用执行计划优化查询
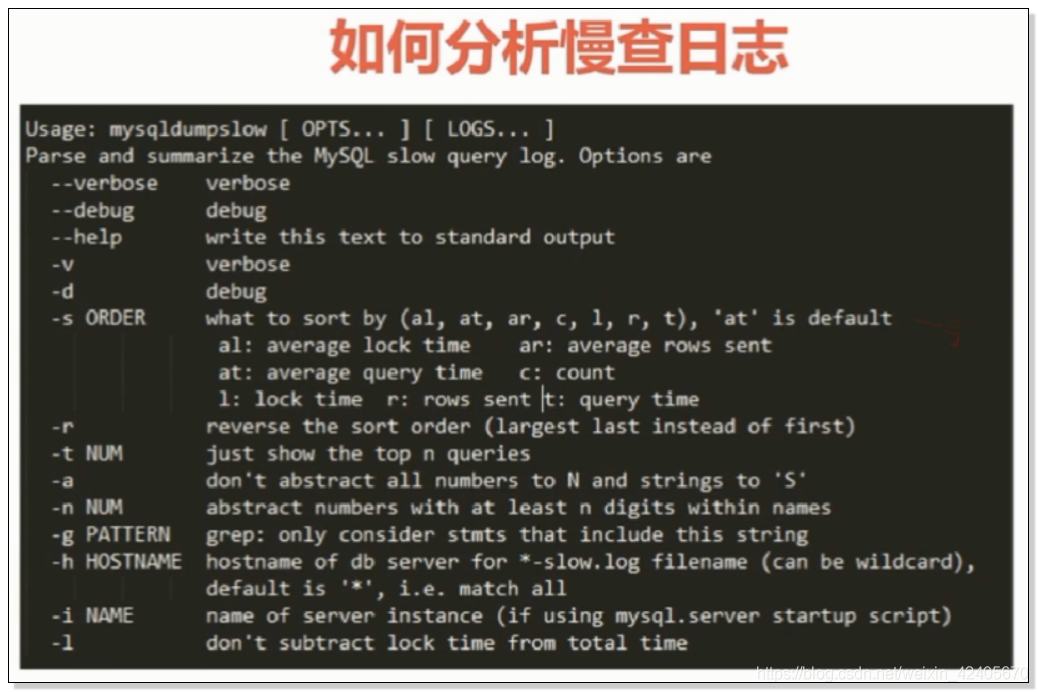
如何找到需要优化的SQL呢? 答案:慢查询日志
启用mysql慢查日志
set global slow_query_log_file = /sql_log/slow_log.log;
set global log_queries_not_using_indexes = on;
未使用索引的SQL记录日志
set global long_query_time = 0.001;
抓取执行超过多少时间的SQL(秒)
set global low_query_log = on;

![]()
![]()
![]()

